






















Teoría Clásica de los Test

.
Por: Sara Valentina Vásquez Riaño
Desde tiempos muy antiguos, las personas han buscado medir distintos elementos del entorno con la intención de comprenderlos mejor. En contextos educativos y de evaluación psicológica esta necesidad se ve reflejada en la medición de las capacidades y características de las personas con el fin de orientar la toma de decisiones. Con este objetivo, surgieron los test como herramientas que permiten estimar el nivel de un atributo en las personas.
Estos instrumentos son útiles para acercarnos a aquellas características que no son observables de manera directa, como la inteligencia, la personalidad o los conocimientos; sin embargo, toda medición que se hace siempre estará acompañada de un grado de error. Como se conoce, los resultados de las evaluaciones suelen tener un impacto significativo en la vida de las personas, por ejemplo, entrar a la universidad, obtener un trabajo o ser diagnosticado, es por esto que los resultados deben ser interpretados en considerando que no se refleja exactamente el nivel real de atributo medido.
De este principio parte la teoría de medición denominada Teoría Clásica de los Test (TCT), la cual permite la aproximación a los resultados de las pruebas considerando el error de medición. Interpretar la información desde este marco permite tener mayor seguridad sobre las mediciones que se hacen, estimando qué tan cercanas están las puntuaciones obtenidas del valor verdadero para así hacer interpretaciones claras que apoyen la toma de decisiones. Aunque han surgido nuevas teorías que brindan mayor precisión en el análisis de las pruebas, como la Teoría de la Generalizabilidad (donde se considera el error generado a partir de distintas fuentes como los ítems, los evaluadores o la aplicación) y la Teoría de Respuesta al ítem (que analiza el comportamiento de cada ítem de una prueba a partir del desempeño de las personas) (Meneses, 2013), la TCT se sigue utilizando dada su facilidad de aplicación y utilidad en los distintos contextos de evaluación. Autores como Cappelleri et al. (2014) recomiendan que sea el primer paso en el proceso de análisis de los instrumentos de medición.

¿Qué es la Teoría Clásica de los Test?
La Teoría Clásica de los Test es un modelo psicométrico que se basa en tres conceptos básicos: la puntuación verdadera, la puntuación del test y el error. Se indica que la puntuación del test (X) corresponde a la puntuación verdadera (V) más un error (e) (Muñiz, 2018; Meneses, 2013).
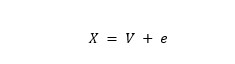
La puntuación verdadera es el valor real del atributo de interés, sin embargo, al hacer mediciones de variables latentes (no observables directamente), sólo es posible una aproximación a estás por medio de la puntuación obtenida en el test, lo cual siempre va a estar acompañada de un margen de error proveniente de distintas fuentes. El error es el motivo por el cual la puntuación empírica no coincide con la puntuación verdadera. Este puede ser de dos tipos: si proviene de factores del momento de la aplicación como la fatiga, el ruido o la motivación del participante se trata de un error aleatorio, mientras que, si se debe a motivos propios de la prueba, como mala redacción, implicaría un error sistemático (Meneses, 2013).
La TCT plantea que, si se pudiera aplicar una prueba un número infinito de veces al mismo sujeto bajo las mismas condiciones, y luego se calcula el promedio de los puntajes obtenidos, se podría conocer el valor verdadero del atributo de esta persona. Adicionalmente, para asumir que a partir de la puntuación obtenida se puede conocer la puntuación verdadera, dentro de la TCT plantean los siguientes supuestos (Meneses, 2013):
- No hay relación entre las puntuaciones verdaderas y los errores de medida, lo que quiere decir que mayor puntuación no implica mayor error.
- Los errores son aleatorios para cada aplicación, lo que implica que no hay relación entre los errores de las aplicaciones de dos pruebas diferentes.
- Se considera que dos versiones de un test son paralelas si tienen la misma puntuación verdadera y el mismo nivel de error.
Bajo esta teoría las dos grandes propiedades que deben tener los test: la fiabilidad y la validez se comprenden de la siguiente manera: la fiabilidad referida a qué tan constante y estables son los puntajes arrojados por el test, una prueba fiable va a arrojar los mismos resultados en distintas aplicaciones (considerando siempre el nivel de alteración por el error), al ser una proporción arroja valores entre 0 y 1, valores cercanos a 0 implican un instrumento menos fiable y valores cercanos a 1 implican una varianza de error más pequeña, con valores más cercanos al valor verdadero (Barrios y Cosculluela, 2013).
Se tienen diferentes métodos para estimar la estabilidad, consistencia y precisión de los resultados de un instrumento: es posible aplicar dos formas paralelas de un mismo test, aplicar el mismo test dos veces al mismo grupo de personas (test-retest) o dividir el test a la mitad y correlacionar los resultados para así evaluar su consistencia interna (Barrios y Cosculluela, 2013; Muñiz, 2018). Igualmente, es necesario calcular la calidad de los ítems que componen la prueba, para esto se suelen utilizar coeficientes como el alfa de Cronbach que nos permite conocer qué tan correlacionados están los ítems en la medición de un mismo constructo y analizar cómo se modifica el valor al eliminar cada ítem para identificar su peso en la consistencia de toda la prueba. Sin embargo, la fiabilidad no es un valor absoluto, pues tiende a variar según ciertos factores, por ejemplo, suele aumentar si se aumenta la variabilidad de las respuestas o el número de ítems del instrumento.
Por otro lado, la validez es un concepto que complementa la estabilidad del test, pues una prueba puede arrojar siempre el mismo resultado, pero podría no tener evidencias de estar midiendo el atributo objetivo, un instrumento que tenga relación teórica con el atributo que se mide va a permitir que las interpretaciones sean válidas y significativas. La validez se compone de distintas fuentes de evidencias que en conjunto respaldan las interpretaciones que se hacen a partir de los resultados, entre estas se incluye qué tanto los ítems representan los elementos asociados al constructo medido (evidencias relacionadas con el contenido), qué tanto se relaciona con otros elementos relacionados con ese atributo, como otros test o predicciones (evidencias relacionadas con otras variables) y qué tanto representa la teoría que la sustenta (evidencias relacionadas con la estructura interna) (Muñiz, 2018).
Dentro de las formas que utiliza la TCT para garantizar que una prueba es fiable y sus interpretaciones son válidas, se encuentra el análisis de las propiedades de cada ítem que compone el test. Buscando reducir el nivel de error que se debe obtener, garantizando el tener parámetros que permitan garantizar que cada ítem está cumpliendo correctamente su función. Entre los parámetros se encuentra la dificultad y la discriminación (junto a la calidad de los distractores en las preguntas de opción múltiple) (Bonillo, 2013).
En primer lugar, el índice de dificultad es la proporción de personas que logran contestar la pregunta correctamente, nos dice que tan fácil o qué tan difícil es un ítem para las personas que lo responden. Al ser una proporción, los resultados posibles van entre 0 y 1, los ítems con valores cercanos a 1 son ítems muy fáciles, es decir, que la mayoría de personas logra contestarlos correctamente, mientras que valores cercanos a 0 implica que pocas personas lograron acertar.
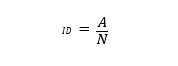
A: Cantidad de personas que aciertan.
N: Cantidad total de personas que contestan el ítem.
Hacer este cálculo resulta importante para identificar ítems muy fáciles e ítems muy difíciles, ya que ninguno de estos nos va a ayudar a distinguir a las personas según su nivel de atributo. A partir de esta información se puede hacer una selección y ajuste de los ítems buscando cómo evaluar varios niveles de atributo.
Como segundo elemento a analizar en el proceso de construcción de los test es la discriminación que tiene cada ítem, ya que adicionalmente interesa saber qué tan bien separa a las personas que tienen un alto o un bajo nivel de atributo. Entre los índices utilizados para hacer esto, Muñiz (2018) presenta los índices planteados en la TCT para hacer esto, entre estos se incluye: la correlación biserial-puntual (para cuando se tiene una variable dicotómica y otra cuantitativa), la correlación biserial (para variables dicotomizadas), el coeficiente phi (para dos variables dicotómicas) y la proporción de aciertos. Este último se basa en comparar las proporciones entre un grupo con alto atributo y un grupo con bajo atributo.
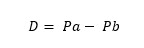
Pa: Proporción de aciertos en el grupo de alto nivel de atributo.
Pb: Proporción de aciertos en el grupo de bajo nivel de atributo.
Esto nos podrá arrojar valores entre -1 y 1. Los cercanos a 1 indicarán que el ítem discrimina muy bien dado que las personas con mayor nivel de atributo tienden a acertar mientras que las personas con bajo nivel tienden a fallar, los cercanos a 0 indica que el ítem no discrimina y los valores cercanos a -1 indica que las personas con bajo nivel suelen contestar correctamente mientras que las personas de alto nivel suelen fallar.
Bonillo (2013) nos recuerda un último punto a tener en cuenta, además de la respuesta correcta, debemos analizar también los distractores en los ítems de opción múltiple, pues para que los ítems sean útiles es necesario que las alternativas a la respuesta correcta ayuden a distraer a aquellos que no tienen altos niveles de atributo. Para saber si un distractor funciona correctamente debemos calcular su discriminación, esperando que esta sea negativa.

¿Para qué sirve la TCT?
Más allá de la comprensión de conceptos teóricos de medición, la TCT va a ser útil para analizar si una prueba está cumpliendo realmente con su función asegurando que las puntuaciones que se obtienen podrán ser consistentes, representen realmente el atributo objetivo y permitan obtener evidencia para tomar decisiones en distintos contextos (Juárez et al., 2025).
En primer lugar, de la mano de los diferentes métodos podemos evaluar la fiabilidad que tiene el instrumento, es decir, que tan consistentes y estables son los resultados que se obtienen en las distintas aplicaciones. Para esto, podemos calcular índices que nos indican en qué grado la prueba está libre de errores de medición, para así saber el grado de seguridad que podemos tener respecto a las interpretaciones hechas a partir de los resultados.
Además, mediante el estudio de la dificultad, la discriminación y el análisis de los distractores, será posible analizar la calidad de los ítems que conforman nuestra prueba, para así identificar cuáles ítems funcionan realmente en la medición de nuestro atributo, cuáles deberíamos modificar y cuáles deberíamos eliminar definitivamente.
El uso que se le da a la TCT va a depender en gran medida de las condiciones en la metodología de la investigación, por ejemplo, va a ser más adecuada cuando se trabaja con muestras muy pequeñas como en la práctica educativa donde se busca garantizar que los exámenes reflejen adecuadamente el aprendizaje del estudiante (Buzo Casanova y García Minjares, 2022); en un contexto clínico ayuda a asegurarnos que los instrumentos estén relacionados con alteraciones o características psicológicas específicas; en el proceso de selección de personas nos va a permitir hacer un análisis comprobando que las herramientas sean consistentes para ayudarnos a tomar las decisiones adecuadas.
Limitaciones de la TCT
Aunque la TCT nos es muy útil en todo el proceso de creación y análisis de las pruebas, presenta también algunas limitaciones que debemos tener en cuenta a la hora de tomar decisiones basándonos en sus resultados. Una de las limitaciones más importantes es su dependencia de la muestra, al calcular la fiabilidad de la prueba y que tan válidos son sus resultados debemos tener en cuenta que el valor va a depender del grupo al que se le aplique la prueba, no son valores universales e invariables de la prueba. Esto podría implicar que una prueba que funciona perfectamente para una población, podría no ser tan precisa en otra (Muñiz, 2018).
Otra limitación relevante es que los resultados van a depender del instrumento con el que se está midiendo el atributo. Es decir, si se midiera el mismo atributo a dos personas diferentes con dos instrumentos diferentes, sus resultados no podrían compararse, lo que implica que no podemos saber quién tiene mayor nivel de atributo (Muñiz, 2018).
Finalmente, también debemos pensar que la TCT analiza el test como un todo, sin enfocarnos en cada ítem, incluso los cálculos que se hacen respecto la dificultad y la discriminación se dan con respecto al total obtenido en la prueba, lo que va a reducir el nivel de detalle que obtendremos y la capacidad de identificar con precisión qué elementos del test están aportando a la calidad de la medición del atributo y cuáles están obstaculizando el proceso, lo que implica que la información que ofrecen estos análisis es más global y se debe tener precaución al tomar decisiones basados solo con esta información.
Es por esto que han surgido nuevas teorías como la Teoría de Respuesta al Ítem, que nos va a permitir superar ciertas limitaciones de la TCT, buscando explicar el funcionamiento de la prueba considerando la relación entre el nivel de atributo que tiene la persona y la probabilidad de contestar correctamente a un ítem (Meneses, 2013).
Para más información sobre la TRI te recomendamos los siguientes blogs:
Si te interesa saber para qué sirve la TRI: https://siepsi.com.co/2025/09/26/la-irt-en-evaluacion-aplicaciones-y-avances/
Si te interesa una función de la TRI en el proceso de validación de pruebas:

Herramientas útiles
Los análisis planteados previamente se pueden llevar a cabo en distintas herramientas que nos van a permitir obtener esta información respecto a la prueba.
En primer lugar, una de las herramientas más utilizadas en el análisis de datos es el software R que junto a su interfaz R studio, nos va a permitir analizar la calidad de nuestra prueba, por ejemplo, el paquete CTT, incluye funciones como score() para calcular el puntaje total de cada persona dentro del test, itemAnalysis() que nos permite obtener el valor de alfa de Chronbach y con $itemReport podemos obtener valores como la dificultad del ítem en itemMean o el Alfa de Cronbach si eliminamos un ítem y la medida de discriminación en pBIS. Además, con la función distractorAnalysis() es posible realizar el análisis de los distractores para los ítems de opción múltiple a partir de la cantidad de personas que escogen ese valor en relación con el número total de participantes (Mendoza Vega, 2022). Una opción más amigable e intuitiva es Lertap 5. Esta funciona como un complemento de excel que permite el cálculo de los valores estadísticos que necesitamos y alfa de Cronbach o sus variaciones al eliminar cada ítem, podemos generar indicadores de dificultad, discriminación y análisis de distractores. Tiene una gran ventaja y es su accesibilidad y facilidad de trabajo (Welcome To Lertap5.com, 2023).
Referencias
Barrios, M., y Cosculluela, A. (2013). Capítulo II. Fiabilidad [PDF]. En Psicometría (pp. 75-140). Editorial UOC. ISBN: 978-84-9064-036-4 https://www.researchgate.net/profile/Julio-Meneses-2/publication/293121344_Psicometria/links/584a694408ae5038263d9532/Psicometria.pdf
Bonillo, A. (2013). Capítulo V. Análisis de los ítems [PDF]. En Psicometría (pp. 231-258). Editorial UOC. ISBN: 978-84-9064-036-4
Buzo Casanova, E. R., y García Minjares, M. (2022). Capítulo 16. Análisis psicométrico de exámentes Teoría de Medicicón Clásica. En Evaluación y aprendizaje en educación universitaria: estrategias e instrumentos (pp. 251-263). Coordinación de Universidad Abierta, Innovación Educativa y Educación a Distancia. ISBN Digital PDF 978-607-30-6071-4 https://cuaed.unam.mx/publicaciones/libro-evaluacion/
Cappelleri, J. C., Lundy, J. J., y Hays, R. D. (2014). Overview of Classical Test Theory and Item Response Theory for the Quantitative Assessment of Items in Developing Patient-Reported Outcomes Measures. Clinical Therapeutics, 36(5), 648-662. https://doi.org/10.1016/j.clinthera.2014.04.006
Juárez, R. C., Sierra, E. A., Hernández, H. D. R., Espinosa, N. B. H., y Munguía, M. A. (2025). Clasificación de ítems de pruebas estandarizadas mediante conjuntos independientes maximales: Un enfoque basado en grafos, Teoría de Respuesta al Ítem y Teoría Clásica de Test. LATAM Revista Latinoamericana de Ciencias Sociales y Humanidades, 6(4). https://doi.org/10.56712/latam.v6i4.4338
Meneses, J. (2013). Capítulo I. Aproximación histórica y conceptos básicos de la psicometría [PDF].
En Psicometría (pp. 25-71). Editorial UOC. ISBN: 978-84-9064-036-4 https://www.researchgate.net/profile/Julio-Meneses-2/publication/293121344_Psicometria/links/584a694408ae5038263d9532/Psicometria.pdf
Mendoza Vega, J. B. (2022). RPubs – Teoría clásica de los test (CTT) – Psicometría con R. Recuperado 17 de septiembre de 2025, de https://rpubs.com/jboscomendoza/ctt_con_r
Muñiz, J. (2018). Introducción a la Psicometría: Teoría clásica y TRI. Ediciones pirámide. ISBN digital: 978-84-368-3933-3
Welcome to Lertap5.com. (2023, 5 noviembre). Recuperado 17 de septiembre de 2025, de https://www.lertap5.com/
Add Comment