






















La psicología detrás del machine learning: Psicólogos que contribuyeron a su evolución

Por Brayam Pineda
Psicólogo especialista en analítica de datos.
Universidad Nacional de Colombia
Aún recuerdo las caras de las personas que me entrevistaron para algunas posiciones como analista o científico de datos cuando les mencionaba que era profesional en psicología. También la intriga del director de posgrados, cuando me presenté a la especialización en analítica de datos y me preguntó “¿Por qué tantos psicólogos se están metiendo al análisis de datos?”. Y como olvidar también cuando en la reunión con mi equipo de trabajo actual, en donde ejerzo como científico de datos, todos hicieron esa cara que uno hace cuando le cuentan sobre hábitos alimenticios extraños en otras partes del mundo. Sí, esa misma, la cara de “¿Qué qué?” He de aclarar que, salvo por algunos entrevistadores en vacantes de empleo, todas eran caras de intriga más que de decepción y condescendencia.
Como psicólogo y científico de datos me he topado muchas veces con la pregunta acerca de ‘¿Por qué escogiste una profesión tan distinta de la que estudiaste?’ o (más frecuentemente) ‘¿Qué tiene que ver eso (el análisis de datos) con psicología?’. Indiscutiblemente, en Colombia, y me atrevería a decir que en gran parte de América Latina, existe un imaginario acerca del psicólogo como un profesional que se dedica principalmente a hacer entrevistas. Bien sea por motivos clínicos, de selección de personal, en los colegios o yendo a comunidades a brindar soporte de alguna forma.

Si bien es algo decepcionante que las personas en general ignoren la amplitud del oficio del psicólogo, es más decepcionante aún que, expertos en estadística y ciencia de datos ignoren la contribución que la psicología ha realizado a los campos de la estadística y del machine learning. Es por eso que, a continuación, ofrezco un breve recorderis de algunas de las principales contribuciones que, como psicólogos, hemos hecho al campo del análisis de datos, y más precisamente al machine learning.
Según Graph EveryWhere (https://www.grapheverywhere.com/algoritmos-de-machine-learning/), empresa líder en grafos y con más de 15 años de experiencia en el sector de datos, los algoritmos más usados en machine learning son:
- Algoritmos de regresión
- Algoritmos Bayesianos
- Algoritmos de agrupación
- Algoritmos de árbol de decisión
- Algoritmos de redes neuronales
- Algoritmos de reducción de dimensiones
- Algoritmos de aprendizaje profundo
Por otra parte, Juan Ignacio Bagnato, ingeniero de sistema de información y quien lleva más de 15 años dirigiendo equipos y realizando consultorías en analítica de datos, propone en su página web https://www.aprendemachinelearning.com/ un listado similar, de los que según su experiencia, son los algoritmos más usados en machine learning:
- Algoritmos de regresión
- Algoritmos basados en la instancia
- Algoritmos de árbol de decisión
- Algoritmos bayesianos
- Algoritmos de clustering (agrupación)
- Algoritmos de redes neuronales
- Algoritmos de aprendizaje profundo
- Algoritmos de reducción de dimensión
- Procesamiento de Lenguaje Natural (NLP)
Pues bien, le sorprenderá al lector saber que detrás de al menos tres de estos algoritmos hay psicólogos pioneros en el campo del machine learning, la estadística predictiva y, sobre todo, de la Inteligencia Artificial. Veámoslos.

1. Algoritmos de regresión:
Los algoritmos de regresión buscan estimar un valor mediante la asociación del mismo con unas variables predictoras, generalmente, buscando la ecuación que minimice el error de predicción. En otras palabras, busca predecir un valor basado en otros valores relacionados.

Tomado de Regresión lineal – Wikipedia, la enciclopedia libre, 2022
Pese a que en ambos artículos es el primer algoritmo mencionado, la regresión es casi invisibilizada cuando se habla de la historia o los hitos del machine learning (Fradkov, 2020; Marr, 2016), esto se debe a que es bastante anterior a las computadoras o al menos a Turing. El primer método de regresión fue desarrollado de forma independiente por Legendre y Gauss (Faraway, 2015), pero fue Francis Galtón, pionero de la psicometría y la psicología diferencial (Colom Marañon, 2018), el que acuñó el término. Galton fue precursor del uso de la distribución normal, introdujo el concepto de correlación y sugirió el uso de procedimientos basados en modelos normales bivariados (Francis Galton, 2021).
Estos aportes fueron desarrollados más tarde por su discípulo, el matemático Karl Pearson, quien finiquitó las matemáticas detrás de la propuesta de Galton y por el psicólogo Charles Spearman, quien contribuyó en el campo de la estadística principalmente con el coeficiente de correlación de Spearman, el cual solventaba algunos inconvenientes que el de Pearson presentaba y, por ello, le ganó una disputa vitalicia con el último. Spearman también desarrolló el análisis factorial (Martínez et. al, 2009; Wikipedia contributors, 2022).
2. Árboles de decisión:
Los árboles de decisión son modelos utilizados principalmente para clasificación. A diferencia de otros modelos, estos se basan en los datos actuales de los atributos y generan un conjunto de reglas que permiten clasificar el resultado. Para que el lector se haga una idea sencilla, son como un diagrama de flujo.
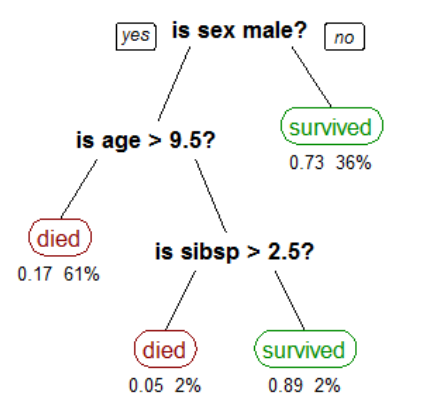
Tomado de Aprendizaje basado en árboles de decisión (2020)
Tal y como lo afirman García et al (2018), fueron Earl B. Hunt, Janet Marin y Philip J. Stone, un grupo de psicólogos, quienes desarrollaron el primer sistema capaz de construir árboles de decisión, CLS, en 1966. Lo anterior, pese a que el primer árbol de decisión fue presentado tres años antes por el economista James N. Morgan y el sociólogo John A. Sonquist (Morgan and Sonquist, 1963). CLS sentó las bases sobre las que Ross Quinlan, ingeniero informático construyó ID3 y sus predecesores (Quinlan, 1986).
Otro de los psicólogos que contribuyó en gran manera a los árboles de decisión fue Jon D. Patrick, psicólogo de la Universidad de Deakin (Jon Patrick, nd), quien en 1993, junto con el científico de la computación Christopher Stewart Wallace, aplica la teoría de Minimium Message Length a árboles de decisión, lo que permite optimizar los árboles en cuanto profundidad, longitud y, por supuesto, recursos computacionales utilizados (Wallace & Patrick, 1993).
Finalmente, tenemos a Brian R. Gaines, psicólogo colegiado por la Sociedad Británica de Psicología, de la que además fue su presidente (Constructivist Psychology Network, 2022). Gaines junto con Paul Compton, desarrollaron el Ripple-down rules learner, el cual es un generador de reglas superior a PART y JRip. Esta metodología se ha propuesto como un optimizador general del machine learning e incluso como su reemplazo (Compton, P., & Kang, B. H., 2021). Tal es su contribución al machine learning, que este psicólogo fue también colegiado por la Sociedad Británica de Ingeniería.
Una historia completa sobre el desarrollo de árboles de decisión se puede encontrar en (https://numerentur.org/arboles-de-decision/)
3. Redes neuronales
Seguramente, si usted conoce algo sobre la historia de las redes neuronales, este era el primer (o el único) algoritmo que esperaba encontrar aquí. Las redes neuronales son, sin duda alguna, uno de los mayores desarrollos del machine learning. Es tanto así, que es lo primero que se viene a la cabeza cuando hablamos de aprendizaje automático o deep learning. Las redes neuronales están compuestas por unidades inspiradas en las neuronas biológicas. Es común que múltiples redes de neuronas se conecten entre sí para la resolución de problemas, entre ellos, regresión, clasificación, computer vision, o procesamiento de lenguaje natural, entre otros. Para conocer más acerca de cómo funcionan, recomiendo https://www.youtube.com/watch?v=MRIv2IwFTPg&list=PL-Ogd76BhmcB9OjPucsnc2-piEE96jJDQ y para conocer una breve historia https://www.aprendemachinelearning.com/breve-historia-de-las-redes-neuronales-artificiales/
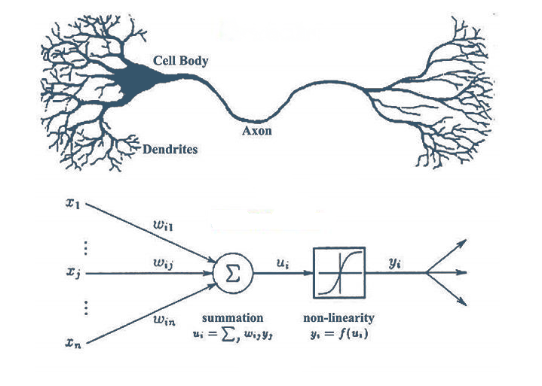
Tomado de Redes neuronales o el arte de imitar el cerebro humano 2019
Fue el psicólogo americano Frank Rosenbalt quien en 1958 crea el perceptrón (Marr, 2016), el cual es la unidad de análisis que hace posible el desarrollo de redes neuronales. Vale la pena aclarar que este avance fue posible gracias a los trabajos del también psicólogo Warren McCulloh y el lógico Walter Pitts, quienes modelaron una red neuronal mediante circuitos eléctricos en 1943 y desarrollaron el Linear Threshold Unit (Neurona de McCulloch-Pitts, 2022).
Basados en estos avances, en 1959 los ingenieros eléctricos Bernard Widrow y Marian Hoff (uno de los creadores del microprocesador) crean MADALINE, la primera red neuronal aplicada a un problema del mundo real, a saber, eliminar el eco producido en las señales telefónicas. No obstante, las redes neuronales tenían serias limitaciones, una de ellas, la incapacidad de resolver problemas XOR (Cuevas Tello, J., 2017). Por otro lado, el valor de los pesos en la ecuación era puesto manualmente. Para dar una idea de la complejidad que implica lo anterior, Lucas Lacasa en su libro Optimización Matemática: en busca de la mejor opción (2019), da el siguiente ejemplo:
“…planteemos un ejemplo de una red profunda <<pequeñita>>, compuesta por 5 capas ocultas y 20 neuronas por capa, con una capa de entrada de 20 neuronas y una capa de salida con una única neurona.. El número de parámetros a optimizar es 20x20x2x5+40= 4040.” (pg. 113)
Dibujando esta red neuronal neuronal ‘pequeñita’, nos quedamos con algo similar a la siguiente figura, y sí, cada línea que usted ve, es un peso diferente.
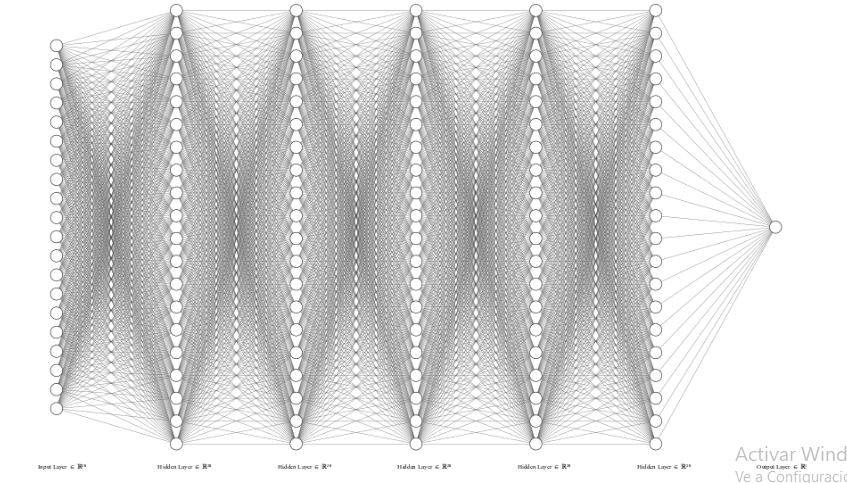
Imagen obtenida mediante http://alexlenail.me/NN-SVG/index.html
Entenderá el lector que es un problema exponencial si se tienen muchas variables, muchas neuronas y muchas capas. Es por esto que entre 1960 y 1985, se hicieron pocos avances en esta técnica en particular.
No fue sino hasta 1986 que los psicólogos David E. Rumelhart y Geoffrey Hinton, junto con el científico computacional Ronald J. Williams, desarrollan el tan popular método de backpropagation, algoritmo que permite entrenar redes neuronales automáticamente y resuelve las limitaciones asociadas a los problemas XOR (Rumelhart, D et al, 1986). Esta técnica permite desarrollar redes neuronales convolucionales y redes neuronales recurrentes.
Finalmente, en 2006 el psicólogo Geoffrey Hinton emplea el término ‘deep learning’ para referirse a aprendizajes de máquina complejos como el reconocimiento de voz, computer vision, entre otros. Hinton es, sin duda alguna, el psicólogo con mayor reconocimiento dentro del campo de la inteligencia artificial y es siempre considerado como uno de los 10 mejores científicos de datos en el mundo (https://www.mygreatlearning.com/blog/top-data-scientists-in-the-world/ y https://www.analyticsinsight.net/top-15-data-science-experts-of-the-world-in-2020/).
Ñapa
Los primeros trabajos sobre reducción de dimensiones se publicaron ambos en revistas de psicología, PCA (Hotelling, H., 1933) y SVD (Eckart, 1936). Lo que da a pensar como bien lo señala Trendafilov (2013) que la medición cuantitativa de las cualidades mentales humanas a principio del siglo XX tenía una importancia tan grande como hoy lo tiene la ingeniería genética o el procesamiento de datos.
Espero que con el contexto anterior el lector haya quedado convencido de la importancia que los psicólogos y la psicología como tal han tenido en el desarrollo del machine learning. Como un último punto antes de terminar, quiero resaltar que en esta reconstrucción histórica noté la invisibilización de la psicología como tal, ya que cuando uno de estos precursores había estudiado matemáticas, física o ingeniería, se referían a éste como tal, mientras que, cuando los profesionales eran del campo de la psicología, decían “referente de la IA” o “científico computacional”, por ejemplo. Lo anterior, según este autor, puede deberse al mismo sesgo alrededor de la analítica como distante a la psicología. Para conocer sobre uniones actuales entre la psicología (más específicamente la psicometría) y el machine learning, lo invito a consultar Psicometría y Machine Learning (https://siepsi.com.co/2022/02/14/psicometria-y-machine-learning/).

Referencias
Aprendizaje basado en árboles de decisión. (2020, 8 de diciembre). Wikipedia, La enciclopedia libre. Fecha de consulta: 21:16, marzo 13, 2022 desde https://es.wikipedia.org/w/index.php?title=Aprendizaje_basado_en_árboles_de_decisión&oldid=131532386
Colom Marañon, R., 2018. Manual de psicología diferencial: Métodos, modelos y aplicaciones. 1st ed. Madrid: Ediciones Pirámide, pp.19-28.
Compton, P., & Kang, B. H. (2021). Ripple-Down Rules: The Alternative to Machine Learning. Chapman and Hall/CRC.
Constructivist Psychology Network. 2022. Brian R. Gaines Receives 2014 Lifetime Achievement Award . [online] Available at https://web.archive.org/web/20140914122723/http://www.constructivistpsych.org/archives/4543 [Accessed 26 febrero 2022].
Eckart, C., Young, G. The approximation of one matrix by another of lower rank. Psychometrika 1, 211–218 (1936). https://doi.org/10.1007/BF02288367
Faraway, J., 2015. Linear models with R. 2nd ed. Boca Raton: CRC Press, pp.1-12.
Fradkov, A. L. (2020). Early history of machine learning. IFAC-PapersOnLine, 53 (2), 1385-1390.
Francis Galton. (2021, 21 de noviembre). Wikipedia, La enciclopedia libre. Fecha de consulta: 21:01, marzo 13, 2022 desde https://es.wikipedia.org/w/index.php?title=Francis_Galton&oldid=139874364 Wikipedia contributors. (2022, March 5). Charles Spearman. In Wikipedia, The Free Encyclopedia. Retrieved 21:09, March 13, 2022, from https://en.wikipedia.org/w/index.php?title=Charles_Spearman&oldid=1075439948
García, J., Molina, J., Berlanga, A., Patricio, M., Bustamante, A., & Padilla, W. (2018). Ciencia de datos. Técnicas Analíticas y Aprendizaje Estadístico. Bogotá, Colombia. Publicaciones Altaria, SL.
Hotelling, H. (1933). Analysis of a complex of statistical variables into principal components. Journal of Educational Psychology, 24, 417–441, and 498–520
Jon Patrick (Sídney). Education [página de LinkedIn]. LinkedIn Recuperado el 26 de febrero de 2022, de https://www.linkedin.com/in/jon-patrick-5a909272/details/education/
Lacasa, L., 2019. Optimización matemática: En busca de la mejor opción. 1st ed. España: Emse Edapp, S.l.
magiquo creamos inteligencia. 2019. Redes neuronales o el arte de imitar el cerebro humano. [online] Available at: <https://magiquo.com/redes-neuronales-o-el-arte-de-imitar-el-cerebro-humano/> [Accessed 26 February 2022].
Marr, B., 2016. A Short History of Machine Learning — Every Manager Should Read. [online] Forbes. Available at: https://www.forbes.com/sites/bernardmarr/2016/02/19/a-short-history-of-machine-learning-every-manager-should-read/?sh=764b2b7415e7 [Accessed 26 February 2022].
Martínez Ortega, R. M., Tuya Pendás, L. C., Martínez Ortega, M., Pérez Abreu, A., & Cánovas, A. M. (2009). El coeficiente de correlación de los rangos de Spearman caracterización. Revista Habanera de Ciencias Médicas, 8(2).
Neurona de McCulloch-Pitts. (2022, 15 de enero). Wikipedia, La enciclopedia libre. Fecha de consulta: 22:33, marzo 13, 2022 desde https://es.wikipedia.org/w/index.php?title=Neurona_de_McCulloch-Pitts&oldid=140975434 Cuevas Tello, J., 2017. Apuntes de Redes Neuronales Artificiales Handouts for Artificial Neural Networks. [Blog], Disponible en: https://arxiv.org/pdf/1806.05298.pdf#:~:text=El problema del XOR es,Rosenblatt en 1957 [8]
Quinlan, J., 1986. Induction of decision trees. Machine Learning, 1(1), pp.81-106.
Rumelhart, D., Hinton, G. & Williams, R. Learning representations by back-propagating errors. Nature 323, 533–536 (1986). https://doi.org/10.1038/323533a0
Trendafilov, N. T. (2013). From simple structure to sparse components: a review. Computational Statistics, 29(3-4), 431–454. doi:10.1007/s00180-013-0434-5
Wallace, C. S., & Patrick, J. D. (1993). Coding decision trees. Machine Learning, 11 (1), 7-22.
Add Comment