





















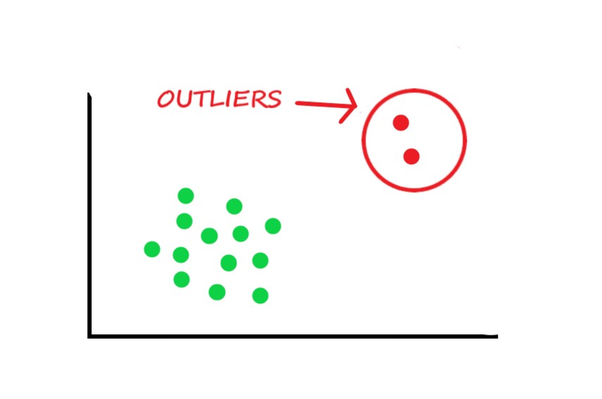
¿Cómo detectar y tratar los outliers?

.
Por: Ana María Angarita Hurtado
Integrante SIEPSI
.
Un outlier o anomalía, es un dato que se aleja de la distribución del resto de la muestra en una o más variables. Debido a lo anterior, generalmente, afecta los resultados al aumentar la varianza del error, reduciendo la potencia de las pruebas estadísticas y propiciando el error tipo I y tipo II, entre otras afectaciones (Ghosh, 2012).
Este blog tiene como propósito presentar una serie de métodos para la detección de outliers, asimismo es importante saber lo qué los causa, la influencia que tienen y decidir si mantenerlos o excluirlos del análisis. Recomiendo al lector acceder a las referencias del blog para profundizar en el método que más le interese o le resulte útil.
Detección mediante asimetría y curtosis:
La curtosis se refiere al grado de apuntamiento de la distribución de frecuencias en comparación con la distribución normal, pudiendo establecerse curtosis positiva, negativa o meso curtosis. Por su parte, la asimetría es un rasgo de la distribución de frecuencias que evidencia la mayor concentración de cierto tipo de datos con base en su posición en la distribución, pudiendo así identificar sesgos en los datos (Levy, 2006). A continuación pueden visualizarse estos conceptos.
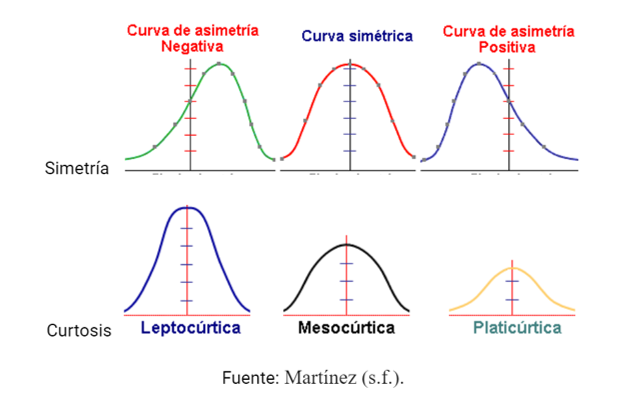
Un valor anómalo será aquel que tenga valores de asimetría superiores al límite de 3 desviaciones estándar con respecto a la media, una forma de detectar outliers es examinando los valores que sobrepasen este límite, antes transformando los datos en puntuaciones típicas z (Verdugo, 2008).
En el caso de la detección de outliers mediante la curtosis, cuando la distribución es normal se obtiene un valor curtosis de 0, mientras que podemos concluir que si se obtiene una curtosis positiva, hay más outliers extremos que los que se evidenciaría en una distribución normal, y si hay curtosis negativa, que los datos presentan valores atípicos menos extremos que una distribución normal (Anónimo, 2021).
Uno de los procedimientos más comunes basado en curtosis consiste en calcular dos espacios p-direccionales con los datos estandarizados: uno con las p direcciones ortogonales de máxima curtosis y otro con las p direcciones ortogonales de mínima curtosis. A partir de este cálculo, se proyecta la nube de datos sobre estos dos espacios direccionales, de modo que los probables outliers serán aquellos datos posicionados en los extremos de alguna de las dos direcciones, es decir, coeficientes de curtosis muy altos o bajos podrán identificarse como potenciales outliers. Para terminar el proceso y conocer con certeza los outliers, se calcula la distancia de Mahalanobis, que es una medida de la distancia multidimensional para cada dato identificado como posible outlier frente a la media de los datos (Marcano, 2013).
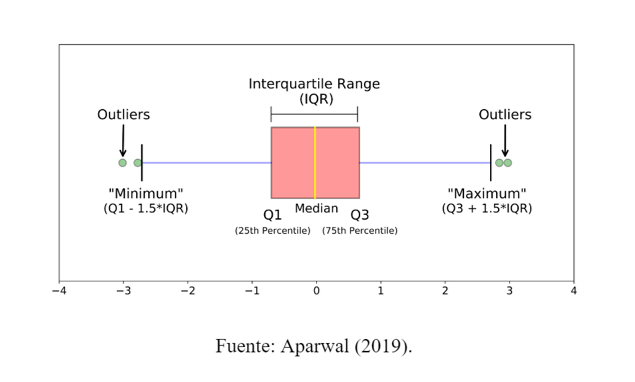
Detección mediante rango intercuartílico:
El rango intercuartílico (IQR) es una medida robusta de dispersión estadística, es la diferencia entre el cuartil tercero y primero, estos coinciden con los límites de la caja del diagrama de caja y bigotes, así pues, la longitud de la caja es igual al rango intercuartílico. El gráfico de caja y bigotes resulta muy útil para la detección de outliers pues representa la distribución de frecuencias con base en cuartiles, en la que los valores atípicos aparecen remarcados. Con base en esto, aquellos datos que sobrepasen los límites, definidos como límite superior: Q3 + 1.5 (IQR) y límite inferior: Q1 – 1.5 (IQR), serán considerados outliers (Moreno, 2014).
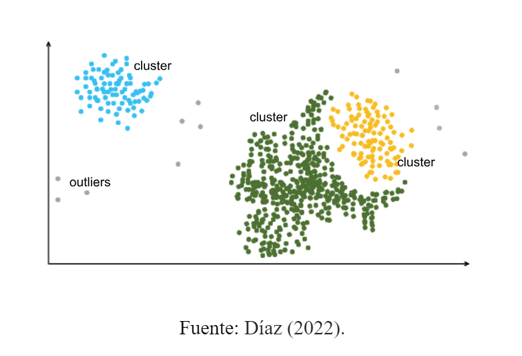
Detección mediante clustering
El método de clustering es una técnica no supervisada y descriptiva de los datos, que busca descubrir agrupaciones naturales en los datos formadas a partir de la cercanía o la similitud entre los sujetos que los conforman. Cada cluster debe cumplir dos reglas, en primer lugar que los datos al interior de los mismos sean lo más homogéneos posibles entre ellos, y en segundo lugar que los datos de un cluster a otro sean tan heterogéneos como sea posible.
Los algoritmos para clustering, además de cumplir muchas otras funciones, son comúnmente empleados para la detección de outliers. Para que un método de cluster cumpla dicha función debe permitir que no todos los datos formen parte de las agrupaciones y debe calcular la probabilidad que tiene cada dato de pertenecer a un cluster. Con base en ello, se considerarán outliers los datos no pertenecientes a ningún cluster, así como aquellos datos cuya probabilidad de pertenecer a algún cluster esté por debajo de un valor mínimo establecido (Rodrigo, 2020).
Detección mediante Isolation Forest:
Isolation Forest es una técnica no supervisada, la cual consiste en una combinación de múltiples árboles que se forman por la separación de los datos a través de la formación de ramificaciones hasta que finalmente cada dato quede aislado en un nodo terminal. Tras este proceso, los datos que resulten atípicos quedarán aislados y el número de nodos para acceder a ellos será menor que para el resto de los datos. Por lo tanto, tras establecer un criterio de distancia de separación, que puede definirse por determinado cuartil, los datos cuya distancia es menor al promedio o a dicho cuartil, podrán identificarse como potenciales outliers (Rodrigo, 2020).
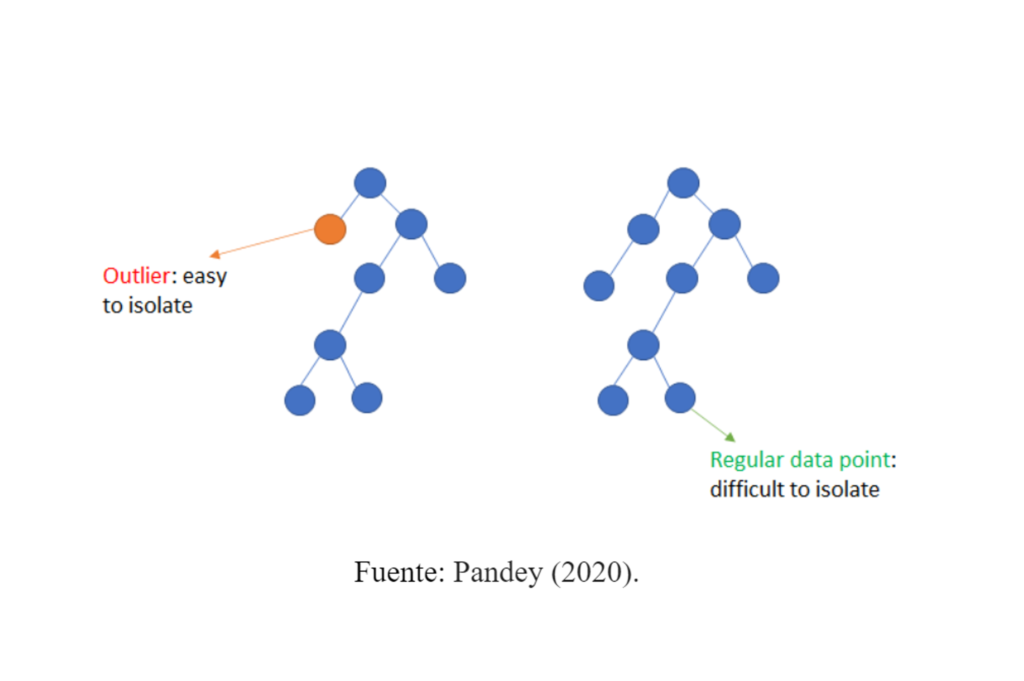
Tratamiento de outliers
Una vez detectados los outliers a través de alguna de las diversas técnicas posibles, es momento de tomar una decisión en cuanto a su tratamiento. Lo fundamental para ello, es la causa de la aparición de los outliers, en el caso de los valores atípicos que son válidos, es decir que aparecen dentro del transcurso adecuado del estudio, es recomendable conservarlos, mientras que si aparecen a causa de un error, deben eliminarse. Si se trata de un problema en el proceso, se debe indagar en este para determinar la causa del valor atípico y corregirlo, también debe verificarse la posibilidad de que se deba a un factor faltante en el proceso, o a un error en la entrada de datos, frente a lo cual se tendría que corregir y volver a correr el análisis (Yepes, 2022).
Una forma de tratamiento alternativa a la eliminación del outlier, corresponde al reemplazo de los outliers por el valor de la media de los datos restantes, esto trae la desventaja de reducir la dispersión poblacional, así como hacer la distribución leptocúrtica y aumentar la probabilidad de un error tipo I. Una tercera técnica a mencionar, consiste en reemplazar los outliers por otros valores posibles dentro de la distribución (Cousineau, 2010).
Referencias
Aparwal, V. (2019). Outlier detection with Boxplots [Gráfico]. Medium. https://medium.com/@agarwal.vishal819/outlier-detection-with-boxplots-1b6757fafa21
Cousineau, D. y Chartier, S. (2010). Outliers detection and treatment: a review. International Journal of Psychological Research, 3(1). http://www.redalyc.org/articulo.oa?id=299023509004
Díaz, B. (2022). Agrupación realizada por DBSCAN [Gráfico]. Impulsatek. https://impulsatek.com/dbscan-un-algoritmo-para-detectar-anomalias/
Ghosh, D. y Vogt, A. (2012). Outliers: An evaluation of methodologies. Joint statistical meetings.
Levy, J., Varela, J., y Abad, J. (2006). Modelización con estructuras de covarianzas en Ciencias Sociales. Netbiblo.
Marcano, L. y Fermín, W. (2013). Comparación de métodos de detección de datos anómalos multivariantes mediante un estudio de simulación. Saber, 25(2).
Martínez, A. (s.f.). Medidas de Distribución – Asimetría y Curtosis [Gráfico]. SPSS FREE. https://www.spssfree.com/curso-de-spss/analisis-descriptivo/medidas-de-distribucion-curtosis-asimetria.html
Moreno, F. (2014). Los outliers en los grupos diagnósticos relacionados. Actualidad médica (793). http://dx.doi.org/10.15568/am.2014.793.or02
Moreno, J. (2012). Método de detección temprana de Outliers. Pontificia Universidad Javeriana. http://hdl.handle.net/10554/10347
Pandey, P. (2020). Outlier Detection using Isolation Forests [Ilustración]. Machine Learning Geek. https://machinelearninggeek.com/outlier-detection-using-isolation-forests/
Resumir estadísticas. (2021). IBM Corporation.
Rodrigo, J. (2020). Detección de anomalías: trimmed k-means. Ciencia de datos
Rodrigo, J. (2020). Detección de anomalía: Isolation Forest. Ciencia de datos.
Verdugo, M., Crespo, M., Badía, M. y Arias, B. (2012). Metodología en la investigación sobre discapacidad. Introducción al uso de las ecuaciones estructurales. VI simposio científico SAID, 2008. http://hdl.handle.net/10366/82465
Yepes, V. (2022) ¿Qué hacemos con los valores atípicos (outliers)? Universidad politécnica de valencia blogs.
Add Comment