






















Limpieza y depuración de datos

.
Por: Brayam Pineda
Integrante SIEPSI
.
Generalmente, en un proyecto de investigación luego de la recolección de datos estamos listos para iniciar con el análisis de la información recogida. Pese a que cada investigación es distinta, para llevar a cabo el análisis de datos, se suele seguir un proceso cuyos pasos suelen ser siempre los mismos, a saber:
- 1) Análisis exploratorio de datos
- 2) Limpieza y depuración de datos
- 3) Análisis descriptivo
- 4) Modelado y pruebas de hipótesis
- 5) Visualización y conclusiones
El análisis exploratorio de datos, conocido como EDA (siglas de la expresión en inglés exploratory data análisis) nos permite conocer qué información es la que tenemos y darnos una idea de qué camino tomar para la limpieza de los datos con el fin de dejar lista nuestra base para los posteriores procedimientos.
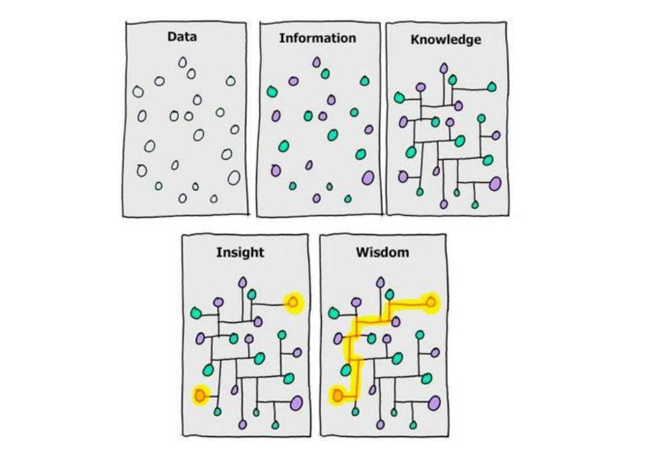
La limpieza y depuración de datos tiene entonces el objetivo de organizar la base de datos de tal forma que pueda sernos útil para la obtención de información, bien sea a través del análisis descriptivo, de pruebas de hipótesis o del modelado de datos. Este paso es sumamente importante, ya que, tal y como lo expresa el dicho popular entre los analistas de datos ‘garbage in, garbage out’, es decir que, si a nuestro modelo entran datos basura, obtendremos resultados inútiles. Ahora bien, la limpieza de datos considera al menos cuatro aspectos:
- 1) Organización de la data
- 2) Detección y tratamiento de datos faltantes
- 3) Detección y tratamiento de outliers
- 4) Estandarización de datos
En este blog analizaremos el primero de estos pasos, la organización de la data, y expondremos algunos de los procedimientos más comunes a la hora de organizar nuestros datos.
¿Qué es una base de datos?
Aunque parezca una pregunta obvia, lo cierto es que usualmente solemos confundir una base de datos con una tabla de datos. Y es que una base de datos es, según Oracle (2022) “una recopilación organizada de información o datos estructurados, que normalmente se almacena de forma electrónica en un sistema informático. Normalmente, una base de datos está controlada por un sistema de gestión de bases de datos”. Seguramente el lector estará pensando que eso es justamente lo que pensaba que era una base de datos al inicio de este blog. No obstante, existen diferencias entre una hoja de cálculo, como las de Excel (que es donde generalmente almacenamos la información de nuestras investigaciones) y una base de datos. Al respecto Oracle (2022) dice:
Las hojas de cálculo se diseñaron originalmente para un usuario y sus características así lo reflejan. Son perfectas para un único usuario o para un pequeño número de usuarios que no necesiten hacer una gran manipulación de datos increíblemente complicada. Las bases de datos, por otro lado, están diseñadas para contener recopilaciones mucho más grandes de información organizada, a veces en cantidades masivas. Las bases de datos permiten que muchos usuarios accedan y consulten los datos de forma rápida y segura al mismo tiempo mediante una lógica y un lenguaje muy complejos.
Para no hacerlo más complejo (porque se puede hacer más complejo) una base de datos requiere de motores de bases de datos como SQL, mientras una hoja de cálculo suele ser una tabla con la información de nuestra investigación. En adelante, siempre que hagamos referencia a la tabla en dónde tengamos nuestra información nos referiremos a ella como data o conjunto de datos.
Tres reglas básicas
Aclarado el tema de las bases de datos, Wickham, H. y Grolemund, G. (2016) señalan que para considerar que un conjunto de datos está ordenado, el mismo debe cumplir tres reglas básicas:
- 1) Cada variable debe estar en una única columna
- 2) Cada observación debe estar en una única fila
- 3) Cada valor debe tener su propia celda.
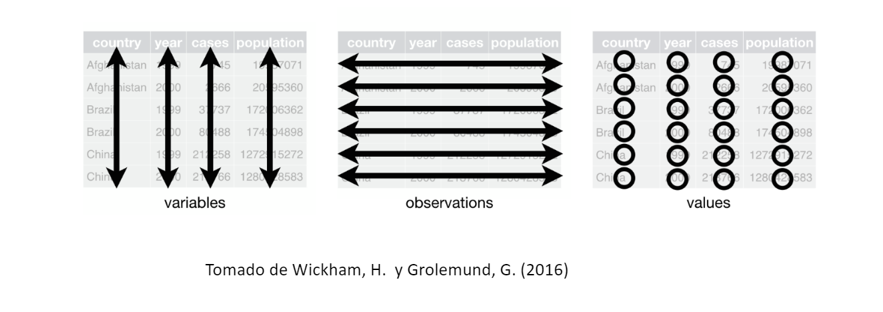
¿Fácil verdad? Y es que, aunque en efecto, es sencillo, lo cierto es que generalmente los conjuntos de datos no son siempre tan amigables. Tan es así que, según Dasu, T. y Johnson, T. (2003) el 80% del tiempo en un proyecto se invierte en la limpieza de datos. Y la principal razón, tal y como la exponen Wickham, H. y Grolemund, G. (2016) es que la mayoría de personas no están familiarizadas con estos principios.
En este sentido, uno de los primeros pasos que usted debe considerar es identificar cuales son las observaciones y cuales son las variables, y aunque parece sencillo considere los siguientes ejemplos
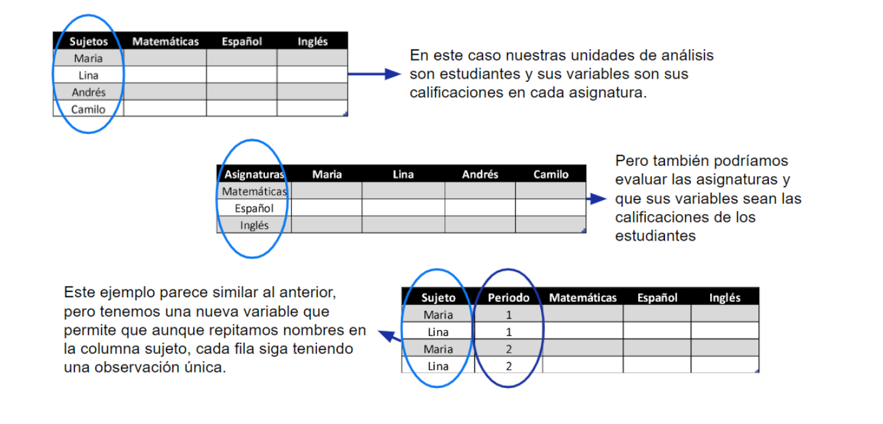
¿Ahora lo ve? Organizar la información va a requerir que usted tenga claro cuál es el propósito de su análisis y además en qué formato debe recibir la información el software que usted vaya a utilizar. Frecuentemente, son cinco los problemas con los que vienen los datos:
- 1) Las columnas son valores y no nombres de valores
- 2) Múltiples variables están almacenadas en una columna
- 3) Las variables están almacenadas en filas y columnas
- 4) Múltiples tipos de unidades observacionales están almacenadas en la misma tabla
- 5) Una sola unidad observacional está almacenada en múltiples tablas
Procedimientos frecuentes en la limpieza y depuración de datos
Ya que conocemos los problemas más frecuentes veamos ahora los procedimientos más frecuentes utilizados en la limpieza de datos:
1. Eliminación de filas y columnas: Y es que, aunque parezca el más obvio, es frecuente que no eliminemos las variables que no vamos a usar o que no son útiles para nuestro análisis. Así también, es común que muchos investigadores no identifiquen las filas que no les van a ser de utilidad.
Un caso especial de este procedimiento es cuando hemos transformado una columna en otra. Por ejemplo, considere tres columnas que contienen el día, el mes y el año, y que fueron unidas en una sola columna que tiene la fecha. Si el objetivo de mi análisis es hacer una tendencia o serie de tiempo, lo mejor es eliminar las tres columnas anteriores ya que pueden hacer más pesada la data. Al respecto, cabe aclarar que siempre que hagamos la transformación de una columna, es recomendable hacerlo en una columna nueva, y con ello evitar retrocesos en caso de un error.
2. Pivoting o mutación: Entiendo que el término no se explique así mismo, no obstante, es la forma usual de llamar el proceso de pasar un conjunto de datos de un formato ancho a uno largo, o viceversa. Y claro, ahora es necesario explicar a qué me refiero con una formato ancho o largo, por lo que le pediré al lector que considere los dos ejemplos a continuación

En el caso anterior, lo que me interesa es analizar el número de casos por año, es por eso que tomo los años que están en las columnas y los paso a las filas, lo anterior es una transformación de ancho a largo.
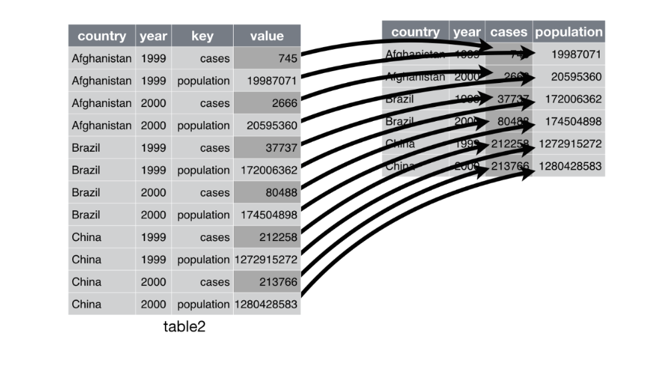
Por otro lado, si lo que me interesa es pasar información de una fila y convertirlas en columnas, hablaremos de una transformación de largo a ancho. Cabe aclarar, tal y como lo mencionan Wickham, H. y Grolemund, G. (2016) que una tabla es más ancha o más larga respecto a otra, no existe un formato ancho o largo por sí mismo.
3. Separación o unión de columnas: Para ilustrarlo podemos basarnos en nuestro ejemplo de las fechas. Si tengo las tres variables día, mes y año separadas en distintas columnas y deseo una fecha en formato dd/mm/yy tendré que unirlas. Por otro lado, si tengo la fecha se encuentra en el formato anterior, y deseo tomar solo los días, tendré que separarlo.
También ocurre mucho en variables categóricas, por ejemplo, si tenemos un atributo que considere la diada “Primer atributo de personalidad saliente – Segundo atributo de personalidad saliente”, por ejemplo basándonos en el Modelo de Personalidad del Big V, podemos tener una celda que contenga “Apertura a la Experiencia – Extroversión”, es posible que según el análisis que queramos realizar debamos separarlo o si queremos analizar las diadas más frecuentes, unirlos.
Finalmente, algunos tips importantes a la hora de organizar nuestros datos son:
– Incluir un encabezado con el nombre de las variables.
– Los nombres de las variables deben ser entendibles (e.g. EdadAlDiagnosticar es mejor que EdDiag).
– Escribir un script con las modificaciones que se hicieron a los datos crudos, lo que apuntaría a que nuestra investigación tenga reproducibilidad.
– Prestar atención a la selección del tipo de variables (fechas) en los programas que aceptan distintos tipos, decidir qué tratamiento se le dará a los datos faltantes y detección de valores atípicos.
– Siempre que esté trabajando con una sintaxis no sobrescriba sus datos, mejor haga una copia del conjunto de datos y trabaje sobre este.
Referencias
Dasu, T., & Johnson, T. (2003). Exploratory data mining and data cleaning. John Wiley & Sons.
Oracle (25 de septiembre de 2022). ¿Qué es una base de datos?. Oracle. https://www.oracle.com/co/database/what-is-database/
Wickham, H., & Grolemund, G. (2016). R for data science: import, tidy, transform, visualize, and model data. ” O’Reilly Media, Inc.”
Add Comment